nanoTRON
The training module uses scikit-learn ‘s multi-layer perceptron (MLP) to train an artificial neural network (ANN). If you use nanoTRON, please cite the publication:
A Auer, M T Strauss, S Strauss, and R Jungmann. ”nanoTRON: a Picasso module for MLP-based classification of super-resolution data”. Bioinformatics, 2020. doi: 10.1093/bioinformatics/btaa154
Detailed recommendation for the use of nanoTRON can be found in the supplementary information, here.
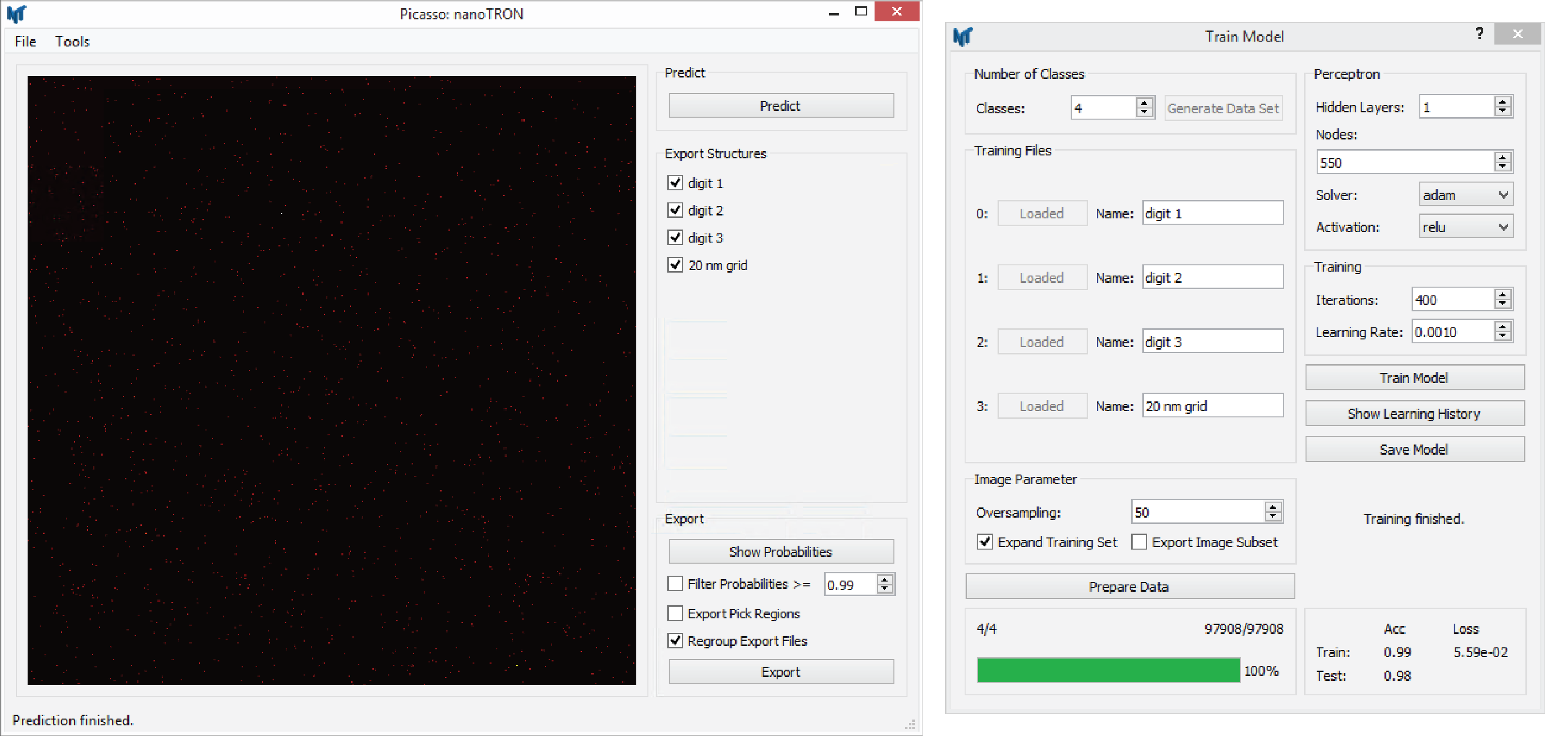
nanoTRON Train
Train a MLP model for nanopattern prediction using nanoTRON.
In
Picasso: nanoTRON, selectTools>Train Modelto open the training user interface.Set the number of different classes of the model via
Number of Classesand pressGenerate Data Set.Load all the training files via the various buttons
Load File. Greyed out buttons indicate that the data set slot is loaded.Name every data set (class) with a unique name.
Set up the image parameters in the box
Image Parameter. Set the oversampling factor viaOversampling. This factor determines the sub-pixel resolution of the training images. We recommend lower resolution as the data would provide for better generalization. Augment the training data sets via the check buttonExpand Training Set. Here every data set point is rotated eleven times. Exemplary images training data images can be exported viaExport Image Subset.If the data is loaded and the image parameters are set, press
Prepare Datato convert the localization (molecule) tables into images.Set up the MLP in the box
PerceptronSet the number of hidden layers viaHidden Layers. The number of nodes in every layer can be set viaNodes. Choose the type of training algorithm via the dropdown boxSolver. We recommend usingadam. Choose the activation function of the layer via the dropdown boxActivation. Note, the activation function can only be set for the whole network.Set up the training in the box
Training. Set the maximum number of iterations (epochs) via the boxIterations. Set the learning rate viaLearning Rate(only necessary if SGD solver is chosen).To start the training, press
Train Model. Depending on the CPU and the size of the training data, this can take up to a few hours.When the training is finished, the learning curve and the confusion matrix can be plotted via
Show Learning History.A summary of the achieved train and test accuracies is given at the bottom of the
Train Modelwindow.Save the model for later use via
Save Model.
nanoTRON Predict
Use a trained nanoTRON model to classify nanopatterns on new data.
Load the model via
Tools>Train Model. The different classes should now be listed on the right side.Drag and drop the Picasso localization table file (HDF5) that should be used for prediction into the large grey box. If the file was loaded correctly, the box displays the image.
Start the classification via the button
Predict.Choose the classes that should be exported in the box
Export Structures. By default, each class is exported.Set the export parameters in the box
Export. The distribution of the prediction probability can be plotted via the buttonShow Probabilities. Optional, set a probability filter via the check buttonFilter Probabilities. Optional, enable the additional export of the pick regions via the check buttonExport Pick Regions. Choose if the new localization files, segmented by the classified nanopatterns, should be regrouped via the check buttonRegroup Export Files. Note, the group id in every exported file start with 0 then. Identification of picks in the original file will be lost.